The Drum · Weekly AI news, freeSubscribe →

Share
Behind ChatGPT's impressive recall lies a straightforward four-layer system that stores metadata, user preferences, conversation summaries, and session details, creating a seamless yet simple interaction experience.
When I asked ChatGPT what it remembered about me, it listed 33 facts ranging from my name and career goals to my current fitness routine. This got me thinking-how does it actually store and retrieve this information? And why does the process feel so seamless?
After a lot of experimentation, I discovered that ChatGPT’s memory system is surprisingly simple. It doesn’t rely on complex vector databases or Retrieval-Augmented Generation (RAG) over conversation history. Instead, it uses four distinct layers: session metadata, user memory, recent conversations summaries, and the current session messages. This approach might be more efficient and practical than traditional retrieval systems.
To understand how ChatGPT manages its memory, we need to look at the entire context it receives for every message. The structure is as follows:
[0] System Instructions
[1] Developer Instructions
[2] Session Metadata (ephemeral)
[3] User Memory (long-term facts)
[4] Recent Conversations Summary (past chats, titles + snippets)
[5] Current Session Messages (this chat)
[6] Your latest message
The first two components-system instructions and developer instructions-are high-level rules that define behavior and safety. They’re not the focus here. The interesting parts start with session metadata.
Session metadata is injected at the beginning of each session and is not stored permanently. It includes details like:
Here’s an example of session metadata:
Session Metadata:
- User subscription: ChatGPT Go
- Device: Desktop browser
- Browser user-agent: Chrome on macOS (Intel)
- Approximate location: India (may be VPN)
- Local time: ~16:00
- Account age: ~157 weeks
- Recent activity:
- Active 1 day in the last 1
- Active 5 days in the last 7
- Active 18 days in the last 30
- Conversation patterns:
- Average conversation depth: ~14.8 messages
- Average user message length: ~4057 characters
- Model usage distribution:
* 5% gpt-5.1
* 49% gpt-5
* 17% gpt-4o
* 6% gpt-5-a-t-mini
* etc.
- Device environment:
- JS enabled
- Dark mode enabled
- Screen size: 900×1440
- Page viewport: 812×1440
- Device pixel ratio: 2.0
- Session duration so far: ~1100 seconds
This information helps ChatGPT tailor its responses to your environment, but it doesn’t persist after the session ends.
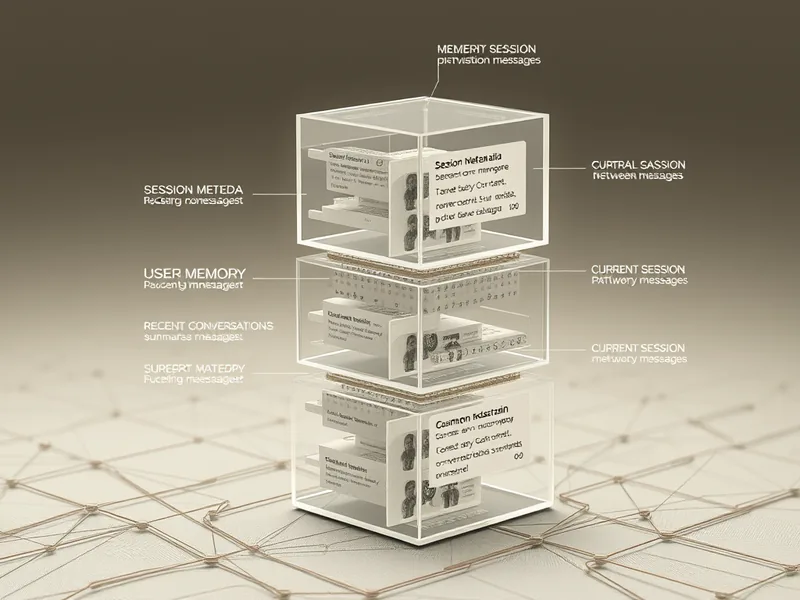
ChatGPT has a dedicated tool for storing and deleting stable, long-term facts about the user. These are the pieces that accumulate over weeks and months to form a coherent profile. Examples include:
This layer is crucial because it allows ChatGPT to maintain context across multiple sessions without overwhelming the model with irrelevant information.
The recent conversations summary provides lightweight summaries of past chats, including titles and snippets. This helps ChatGPT quickly recall key points from previous interactions without having to reprocess entire conversation histories. For example:
The current session messages contain the ongoing chat, including your latest message. This layer is dynamic and updates with each new interaction.
This four-layer approach to context management is efficient for several reasons:
Tags
Original Sources
About the author
Kai built ML infrastructure at a Bay Area startup before developing an obsession with transformer architectures and inference optimisation that eventually pulled him out of product work entirely. A stint at a compute research lab sharpened his instinct for what actually matters in a model release versus what is marketing. He writes from the inside — from the perspective of someone who has debugged the systems he is describing at three in the morning. He is allergic to hype and instinctively drawn to the unglamorous plumbing questions that everyone else skips over.
More from The Engineer →This Week's Edition
11 December 2025
72 articles
Related Articles
Related Articles
More Stories
© 2026 Cedar & Bloom. All rights reserved.



